1. Contexte et typologie du devoir
Dans le cadre de l’objet d’étude « La littérature d’idées et la presse du 19e au 21e siècle » en 2de, le professeur a choisi d’orienter la réflexion de ses classes sur le rôle et l’inscription du journaliste dans son époque.
Quatre ouvrages sont proposés en lecture cursive aux élèves :
- Voyage au Congo d’André Gide
- Terre d’ébène d’Albert Londres
- L’Esclave du lagon de Didier Daeninckx
- La Fissure de Carlos Spottorno et Guillermo Abril.
Ces lectures visent à préparer la réflexion sur le personnage du journaliste comme écrivain engagé :
- les deux premiers ouvrages dénoncent, chacun à leur façon, l’exploitation des populations locales par les colons français dans les possessions françaises de l’Afrique équatoriale (en 1927 pour André Gide, en 1929 pour Albert Londres) ;
- le roman de Didier Daeninckx s’attaque en 2014 à la question du travail des enfants qui, poussés par la misère, se vendent comme « esclaves volontaires » aux Philippines ;
- enfin, la bande dessinée de Carlos Spottorno et Guillermo Abril, conçue comme un reportage photographique et publiée en France en 2017, donne à voir la détresse des réfugiés en sept reportages qui questionnent les choix de l’Europe face à leur afflux.
Pour évaluer l’appropriation personnelle de l’œuvre par chacun, il a été proposé aux élèves de répondre à cinq questions volontairement ouvertes :
- 1. Pour quelle(s) raison(s) avez-vous choisi ce livre et pas l’un des autres ?
- 2. Quel(s) problème(s) le ou les auteurs dénoncent-ils dans cet ouvrage ? Comment s’y prend ou s’y prennent-ils ? Cette dénonciation vous paraît-elle efficace ? Pourquoi ?
- 3. Quel personnage vous paraît le plus intéressant ? Pourquoi ? Pourriez-vous être ce personnage ? Pourquoi ?
- 4. Quel est le passage qui vous a le plus marqué ou la plus marquée dans ce livre ? À quelle musique (ou type de musique) l’associeriez-vous, et pourquoi ?
Sur Terre d’ébène, L’Esclave du lagon et Voyage au Congo :
- 5. a. Proposez une nouvelle illustration de couverture (dessin, collage combinant plusieurs images...). Expliquez et justifiez vos choix d’illustrateur ou d’illustratrice.
- b. D’après vous, ce livre gagnerait-il à intégrer des images ? Lesquelles et pourquoi ?
Sur La Fissure :
- 5. Écrivez une lettre aux auteurs pour leur expliquer quel effet leur livre a produit sur vous (20 lignes minimum). Vous adopterez la présentation et les codes du genre épistolaire (adresse au destinataire, formule de prise de congé, etc.), et prendrez appui sur l’ensemble du livre (texte et images).
Lors de la correction des travaux, il s’avère que le recours à l’intelligence artificielle (IA) est suffisamment massif et maladroit pour être détecté.
2. Les réponses générées par IA : des caractéristiques reconnaissables
C’est très majoritairement dans les travaux sur L’Esclave du lagon que se manifeste le recours à une intelligence artificielle générative. Ce court roman de Didier Daeninckx évoque la vie d’« esclave volontaire » d’un jeune Philippin, Crisanto, contraint de se « vendre » comme pêcheur en apnée pour subvenir aux besoins de sa famille, ruinée par un cyclone.
Dans la plupart des copies concernées, les réponses aux questions 2 et 3 s’avèrent particulièrement intéressantes et révélatrices. Si chacune peut sembler suspecte en elle-même, c’est surtout leur confrontation, d’une copie à l’autre, qui finit par interroger le correcteur.
Voici des extraits de ces réponses :
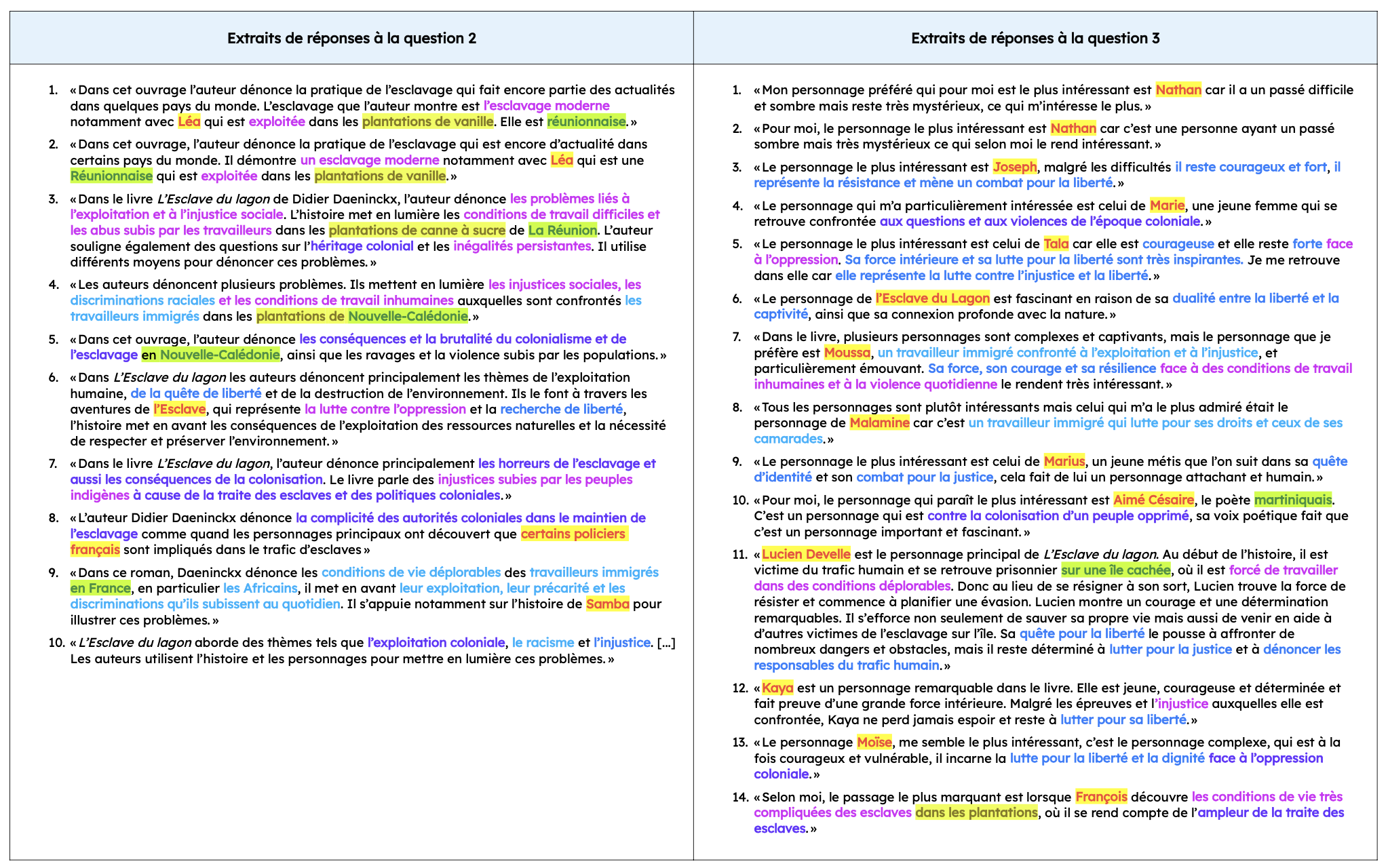
D’emblée, plusieurs erreurs de fond sautent aux yeux.
- Sur le lieu de l’intrigue (passages surlignés en vert) : lorsque ce dernier est situé géographiquement, les réponses le positionnent à La Réunion (3 occurrences), en Nouvelle-Calédonie (2 occurrences), en Martinique (1 occurrence) ou même en France (1 occurrence) ; jamais les Philippines, lieu réel de l’action, ne sont mentionnées. En revanche, l’idée que l’histoire se déroule sur une île paraît bien ancrée, avec même, dans une réponse, une référence à une « île cachée ».
- Sur les noms des personnages (passages surlignés en jaune) : à part dans deux copies par ailleurs étrangement similaires, les noms de personnages ne sont jamais les mêmes. Français ou africains, ils tranchent sur ceux du roman, d’origine philippine ou espagnole [1] : Crisanto, Rizal, Ligaya, Lani, Diwata, Raina, Kidlat, Bayani, Honesto, Pacifico, Jethro, Arnel, Benigno, le capitaine Magtanggol, Datu…. L’évocation d’Aimé Césaire ou d’un personnage de « jeune métis » interpellent particulièrement.
- En corrélation avec l’erreur sur les lieux, l’esclavage envisagé est principalement l’esclavage colonial associé à la traite négrière au 18e siècle. Les réponses mentionnent à plusieurs reprises le travail dans les plantations (surligné en vert pâle), qu’il s’agisse de canne à sucre ou, de façon plus surprenante, de vanille [2] ; ce type d’esclavage n’a rien à voir avec celui dénoncé dans L’Esclave du lagon, où des enfants philippins de notre époque, poussés par la misère, se vendent « volontairement » à des capitaines de navires qui les utilisent pour la pêche en apnée.
- La référence à l’esclavage dans le contexte de la colonisation (en violet) se double d’une dénonciation des méfaits du colonialisme (en rose fuchsia) : les personnages sont décrits comme « exploités », confrontés à des conditions de travail « difficiles » voire « inhumaines », amenés par conséquent à lutter contre l’« injustice » et l’« oppression ».
- Partant dans une autre direction tout aussi erronée, certaines réponses analysent le roman comme une dénonciation des conditions de vie des immigrés en France (en bleu clair).
- Dans tous les cas, revient l’idée que les personnages, majoritairement présentés comme « courageux » et « forts », sont engagés dans une lutte un peu abstraite pour la justice et la liberté (en bleu dans le corpus) : si celle-ci est bien présente dans le roman de Daeninckx, ce dernier reste cependant davantage centré sur la dénonciation du travail des enfants, ainsi que de la misère et des ravages causés par une catastrophe naturelle.
Du point de vue de la forme, l’intervention de l’IA se manifeste également par le recours à une syntaxe et à un lexique qui ne sont habituellement pas ceux des élèves concernés.
On peut ainsi relever :
- des emprunts à l’anglais [3] : par exemple, l’utilisation abusive du verbe démontrer dans la réponse 2 à la question 2 (« Il démontre un esclavage moderne ») ;
- une tendance à présenter les personnages de manière stéréotypée, sans jamais se référer aux passages qui illustrent les qualités qu’on leur prête : « il reste courageux et fort », « elle est courageuse et elle reste forte face à l’oppression », « sa force, son courage et sa résilience face à des conditions de travail inhumaines et à la violence quotidienne le rendent très intéressant », « on [le] suit dans sa quête d’identité et son combat pour la justice »…
- parfois, une forme de lyrisme qui repose souvent sur l’emploi d’expressions toutes faites, parfois grandiloquentes, souvent creuses, et qui rend le propos exagéré (« les aventures de l’Esclave, qui représente la lutte contre l’oppression et la recherche de liberté » (question 2, réponse 6) - en soi, le fait de désigner le personnage par sa catégorie sociale et non par son nom a de quoi surprendre).
À titre de comparaison, voici la réponse de l’une de ces élèves à une question similaire dans un devoir sur la Médée de Jean Anouilh, réalisé plus tôt dans l’année, sans recourir à l’IA. Nous conservons volontairement son orthographe :
Dans ce livre je me sens plus proche de personne parce que tout les personnage sont horrible. Parce que Médée c’est une sorciere. Jason c’est un trahtre, les enfant sont inocent et tuer sant raison, la nourice regrarde tout la tragedie mais elle ne fait rien. Mais Medée est comme une héroïne tragique, notament à cause de son caractère. En vrai elle est juste naïve est prété a tout pour l’amour de Jason. Mais elle n’a rien eu, elle a eu l’amour noir de Jason.
On remarque, dans cette réponse, la caractérisation de la nourrice, visiblement jugée trop passive par l’élève : celle-ci, comme c’est souvent le cas pour les élèves faibles, ne nomme cependant pas ce défaut, mais se contente de décrire le comportement du personnage (« la nourrice regarde toute la tragédie mais elle ne fait rien »). Pas plus que l’IA, l’élève ne se réfère de façon précise au texte ; cependant, elle propose une interprétation du comportement de Médée (« En vrai elle est juste naïve et prête à tout pour l’amour de Jason ») qui implique un positionnement personnel. [4]
3. Que s’est-il passé ?
De toute évidence, la ou les intelligences artificielles utilisées par les élèves ne connaissaient [5] pas L’Esclave du Lagon. Confrontées aux questions posées par les élèves, elles ont donc fait ce que font les IA génératives quand elles ne connaissent pas les réponses : elles les ont « hallucinées », c’est-à-dire générées automatiquement à partir de calculs de probabilités, le probable remplaçant, pour l’IA, le possible.
Concernant l’IA générative, on nomme hallucination la production de contenus erronés que l’on peut classer en trois catégories :
- erreurs factuelles : l’IA fournit des informations incorrectes ou invente des faits. Par exemple, elle attribue à un événement historique une date incorrecte, ou invente un livre qui n’existe pas ;
- erreurs de cohésion textuelle : l’IA crée des réponses qui semblent logiques dans le contexte de la conversation mais qui n’ont aucun fondement dans la réalité ;
- erreurs de synthèse : l’IA fusionne incorrectement des éléments vrais et faux, créant ainsi une réponse partiellement incorrecte.
Ces erreurs peuvent provenir des données d’entraînement, qui contiennent parfois des informations incorrectes ou non-vérifiées, ou bien du modèle de prédiction qui fait que ces IA prédisent le mot ou la phrase suivante d’après les données sur lesquelles elles ont été entraînées, sans véritable compréhension du contenu ni vérification de sa véracité, les IA étant par ailleurs incapables de faire l’expérience des faits qu’elles énoncent. Ces hallucinations peuvent également découler d’une absence de contexte ou d’une transformation de ce dernier par le jeu des algorithmes. Pour combler des lacunes dans ses connaissances, l’IA peut parfois inventer des détails qui semblent plausibles mais qui sont en réalité totalement fictifs.
Les hallucinations sont souvent difficiles à détecter, car elles sont généralement mélangées à des informations correctes.
A. LES HALLUCINATIONS : QUEL POINT DE DÉPART ?
Pour produire ces hallucinations, les IA sollicitées par les élèves ont vraisemblablement d’abord été orientées par le titre L’Esclave du lagon : le mot esclave convoque la forme d’esclavage vraisemblablement la plus représentée dans les corpus avec lesquels elles ont été nourries : la traite des noirs entre l’Afrique et l’Amérique, déportés pour y travailler dans des plantations de coton et de canne à sucre. En passant, ces plantations sont devenues des plantations de vanille, car en termes de probabilités, à Madagascar ou à La Réunion, la vanille fait partie des possibles. Le mot esclave renvoie également à la colonisation, et automatiquement, le texte généré a mobilisé la notion de colonialisme pour en dénoncer les méfaits. La Réunion a été colonisée par les Français : les calculs statistiques ont donc situé l’intrigue du roman sur cette île.
Toujours dans le titre, le mot lagon a d’ailleurs sans doute précisément renforcé la probabilité que l’action prenne place sur un atoll.
Par ailleurs, certains élèves avaient visiblement mentionné le nom de l’auteur : Didier Daeninckx. L’Esclave du lagon ne faisait pas partie du corpus de textes des IA ; en revanche, elles possédaient manifestement des données sur son roman le plus connu, Cannibale. Ce dernier ne débute pas dans les Philippines, mais en Nouvelle-Calédonie, autre colonie française à l’époque de l’intrigue. On y dénonce le mépris des colons français vis-à-vis de la population locale, les Kanaks, dont certains membres sont déportés en France à l’occasion de l’Exposition coloniale de 1931, afin d’y être exhibés comme « cannibales ». Statistiquement, il était donc vraisemblable d’envisager une intrigue dénonçant « la brutalité du colonialisme » en Nouvelle-Calédonie.
B. LES HALLUCINATIONS : QUEL PROCESSUS ?
Pour comprendre le détail de ce processus, il est possible de s’appuyer sur une plateforme spécialement conçue pour sensibiliser les élèves au fonctionnement de l’IA : l’outil de génération de texte de Vittascience [6] (cliquez sur la vignette ci-dessous pour y accéder).
L’intérêt de cette plateforme est de donner accès aux rouages de la machine, en permettant notamment :
- de visualiser les tokens, groupes de caractères à partir desquels l’IA générative « prédit » les caractères suivants ;
- de jouer sur le degré plus ou moins « aléatoire » de cette prédiction ;
- de varier les modèles de langage utilisés, de Mixtral à Llama en passant par GPT [7].
Un token est une unité élémentaire de texte utilisée dans le traitement du langage naturel. Il peut s’agir d’un mot, d’une partie de mot, d’une syllabe, ou même d’un seul caractère ou d’un signe de ponctuation.
Les grands modèles de langage comme GPT-4 utilisent les tokens pour analyser et générer du texte. Lors de la génération de texte, le modèle prédit le token suivant dans une séquence en se basant sur les tokens précédents. Ce processus est itératif et continue jusqu’à ce que le modèle génère une séquence de texte complète.
Prenons un exemple simple. Si nous donnons le texte suivant comme entrée :
- Les chats aiment
Le modèle va convertir cette entrée en tokens, ce qui peut donner quelque chose comme :
- [Les, chat, s, aim, ent]
Ensuite, il utilisera ces tokens pour prédire le prochain token. En s’appuyant sur ses connaissances et les éléments contextuels, il pourra par exemple prédire ceci :
- [Les, chat, s, aim, ent, jouer]
Puis continuer avec des prédictions supplémentaires :
- [Les, chat, s, aim, ent, jouer, avec, des, balle, s].
Dans cette simulation, la conversion en tokens permet de gérer la prédiction de mots, mais aussi les accords au pluriel [8].
Dans l’exemple qui suit, l’utilisation du générateur de texte de Vittascience permet d’illustrer la façon dont les réponses de l’IA sont générées, en montrant comment la modification d’un seul token provoque la génération d’une histoire entièrement différente (cliquez sur l’icône « plein écran » en bas à droite de la vidéo pour l’agrandir) :
Très simple à réaliser en classe, cette manipulation peut permettre d’initier les élèves au fonctionnement essentiellement statistique de l’IA et de leur faire porter un regard éclairé sur ces outils en les démystifiant.
4. Toutes les IA sont-elles équivalentes ?
Dans les réponses du générateur de texte de Vittascience présentées ci-dessus, il est évident que le problème principal provient du fait que l’IA n’a pas connaissance de l’existence de L’Esclave du lagon, et n’a par conséquent aucune information à son sujet. Pour vérifier à quels types de réponses les élèves pouvaient être confrontés avec les IA « grand public », l’auteure de ces lignes a effectué des tests avec trois d’entre elles, en juin 2024 :
- ChatGPT peu de temps après l’implémentation de GPT-4o ; cette IA ne peut être utilisée que sur création de compte, et ne peut donc être recommandée aux élèves, même dans sa version gratuite ;
- Perplexity (www.perplexity.ai) sans création de compte ;
- Microsoft Copilot (copilot.microsoft.com) sans création de compte.
Les résultats sont consignés dans le document ci-dessous (cliquez sur la vignette pour agrandir) :

Nous avons abrégé la réponse de ChatGPT, qui était assez longue. Le passage supprimé contenait des considérations sur les méthodes de dénonciation mises en œuvre dans le roman, et sur leur efficacité. Comme celles portant sur ce qui est dénoncé, elles étaient hallucinées par la machine.
Dans cette réponse, on retrouve les mêmes références erronées à la colonisation, aux conflits entre colons et autochtones, aux violences coloniales, que dans la réponse du générateur de texte de Vittascience ou dans celles proposées par les élèves. Viennent se greffer sur tout ceci l’exploitation des ressources naturelles et la dégradation environnementale, qui ne sont pas non plus au cœur de L’Esclave du lagon. Cette IA, dans sa version gratuite, n’a pas accès à internet en temps réel, et se contente d’halluciner une réponse vraisemblable, sans prévenir qu’elle n’a pas les informations.
La réponse de Perplexity sans création de compte a le mérite de ne pas induire en erreur : l’IA, qui a la capacité de vérifier ses sources, évite l’hallucination, et explique très sobrement qu’elle ne dispose pas des informations pour répondre.
La réponse de Copilot sans création de compte va quant à elle bien plus loin : même sans compte, cette IA a accès à internet en temps réel, et est donc susceptible d’aller y chercher les informations qui lui manquent. Comme on peut le constater, sa réponse est la plus juste des trois : le lieu est exact, le nom du personnage principal aussi ; les catastrophes naturelles, leurs conséquences économiques, et les caractéristiques particulières des « esclaves » dans ce roman sont évoquées avec précision.
Dans sa version avec création de compte, Perplexity fournit toutefois une performance supérieure à celle de Copilot :

Comme Copilot, Perplexity avec compte :
- accède à internet, ce qui lui permet de prendre en compte les données en temps réel ;
- cite ses sources (ici, Amazon, les éditions Larousse, la FNAC…), ce qui permet de les vérifier et de porter sur elles un regard critique.
On voit que par rapport aux réponses de Copilot, celle de Perplexity avec compte traite beaucoup mieux la question de l’efficacité de la dénonciation, même si sa réponse nécessite encore d’être relue et modulée (à la fin, le point 4 sur l’appel à l’action s’appuie visiblement sur une publicité de l’éditeur).
Contrairement à ce qui se produit avec Perplexity, la création d’un compte sur Copilot n’améliore pas significativement la qualité de sa réponse [9].
5. Comment sensibiliser les élèves au fonctionnement de l’IA et à ses biais ?
Dans ce cas précis, on peut tirer parti du grand nombre de réponses à la fois aberrantes et néanmoins convergentes pour le transformer en corpus d’étude pour la classe et, ainsi, sensibiliser les élèves au fonctionnement et aux biais de l’IA.
Voici une proposition de déroulé de séance relativement simple à mettre en œuvre, en cinq temps.
- Temps 1 - Confrontation aux corpus : le professeur distribue aux élèves les corpus de réponses donnés plus haut. Il les lit avec eux ou les leur fait lire. Rapidement, certains s’étonnent des noms de lieux et de personnages. Les premières exclamations fusent : « Ce sont des gens qui n’ont pas lu le livre ! ».
- Temps 2 - Repérage des éléments problématiques et des récurrences : le premier moment de rire ou de sourire passé, le professeur leur fait repérer ce qui pose problème dans le corpus, et surtout, quels sont les éléments récurrents, au niveau du contenu mais aussi du style. Sur le plan du contenu, il est possible que des élèves de 2de ne réagissent pas immédiatement aux mentions du colonialisme ; en revanche, il est assez simple de leur faire repérer les clichés sur l’esclavage (lieux, caractéristiques des personnes concernées…). Sur le plan stylistique, ils peuvent repérer dans le second corpus la présence récurrente d’un lexique de l’émotion qu’ils ont peu l’habitude de mobiliser : inspirantes, fascinant, captivants, émouvant, etc., ainsi que de nombreux noms abstraits : résistance, justice, injustice, liberté… Certaines expressions, comme celle de la « voix poétique » d’Aimé Césaire, ne ressemblent pas à celles que l’on trouve habituellement sous leur plume. Petit à petit, les élèves entrent ainsi dans un regard critique sur les caractéristiques des textes générés par l’IA. Il pourrait du reste être intéressant, à partir de ces constats, de les faire réfléchir aux enjeux d’un écrit d’appropriation et aux leviers ici offerts par l’IA pour enrichir leur expression.
- Temps 3 - Explication du fonctionnement de l’IA : une fois identifiée la présence de nombreux stéréotypes dans le corpus de réponses, il est facile d’expliquer sommairement le fonctionnement par probabilités des IA génératives, en prenant appui, comme nous l’avons fait, sur le titre du roman et sur une présentation rapide de son auteur. Ici, ce fonctionnement apparaît de manière transparente.
- Temps 4 - Test de la génération de texte par tokens : sur les ordinateurs des élèves ou au tableau numérique, on mobilise le générateur de texte de Vittascience, pour leur faire tester par eux-mêmes la génération d’une réponse à l’une des questions, et la modification de quelques tokens, comme nous l’avons fait plus haut.
- Temps 5 - Conclusion sur les précautions prendre avec l’IA (à ce stade, plusieurs élèves font remarquer qu’ « il faut lire le livre »), ainsi que sur les « utilisations vertueuses » de l’IA : comme le suggèrent d’autres élèves, il est par exemple possible de l’utiliser en prenant appui sur ses réponses, mais en les vérifiant et en les complétant (en ajoutant notamment des exemples, un point de vue plus personnel…), ou pour améliorer son écrit.
6. Pour quels bénéfices ?
Au terme d’une séance comme celle-ci, les élèves, qui ont été invités à décrypter les productions de l’IA, portent un regard plus lucide sur ces dernières. Ils savent désormais d’expérience que le fonctionnement de l’IA est exclusivement basé sur des statistiques déterminées au cours de son apprentissage, qu’elle est susceptible de produire des « hallucinations », et que les textes qu’elle génère doivent donc faire l’objet de vérifications et être soumis à un regard critique.
Par ailleurs, ce travail sur les productions de l’IA peut conduire, avec les élèves, à une réflexion plus poussée sur les objectifs et attendus du devoir, en particulier sur les éléments qui donneront le sentiment d’une expérience personnelle de lecteur, d’un contact personnel avec le texte.
Pour le professeur, ce travail pose également la question de ce que l’on évalue, et comment. Avec des IA performantes comme Perplexity dans sa version avec compte, ce qui est évalué sera moins, pour certains élèves, la capacité à synthétiser soi-même les éléments du roman que celle à sélectionner les idées pertinentes de l’IA, les développer, les enrichir d’exemples personnels. Il devient alors possible d’imaginer deux types de devoirs :
- ceux produits seuls, dans lesquels on évalue la qualité du dialogue entre le lecteur et le roman,
- et ceux produits avec l’aide de l’IA, dans lesquels l’échange se fait à trois voix.
Pour aller plus loin : une sitographie sélective
Traitement automatique du langage et le fonctionnement des grands modèles de langage :
- « L’IA est-elle capable d’interpréter ce qu’on lui demande ? », par Rémy Demichelis, The Conversation, juin 2024
- « Traitement automatique des langages : do you speak computer ? », avec François Yvon et Laurent Besacier, 5 janvier 2022, sur France Culture
- « Une petite introduction au traitement automatique des langues naturelles », par François Yvon (ISIR - CNRS/Sorbonne Université), janvier 2007
- « Apprendre les langues aux machines » : captations vidéo du cours de Benoît Sagot (INRIA) au Collège de France, du 8 décembre 2023 au 9 février 2024 (leçon inaugurale le 30 novembre 2023)
IA et enseignement :
- « ChatGPT : face aux artifices de l’IA, comment l’éducation aux médias peut aider les élèves », par Divina Frau-Meigs, The Conversation, juin 2023
- « L’IA à l’école : qu’est-ce qui est de la triche, qu’est-ce qui est correct ? », École branchée, 3 novembre 2023
- IA pour les enseignants : un manuel ouvert, par Colin de la Higuera, Jotsna Iyerle et al. (projet AI4T, Artificial Intelligence for and by Teachers)
